Handling Billions of LLM Logs with Upstash Kafka and Cloudflare Workers

Problem

Important: We desperately needed a solution to these outages/data loss. Our reliability and scalability are core to our product.
Introduction
At Helicone, an open-source LLM observability platform, we faced significant challenges scaling our logging infrastructure to match our growing user base. Our proxy, built on Cloudflare Workers, efficiently handled routing LLM requests, but our logging system struggled with high-volume data processing. This technical deep dive explores how we implemented Upstash Kafka to solve these challenges, detailing our architecture, implementation process, and key technical decisions.
Whether you're currently handling millions of logs and anticipating growth, or already dealing with billions of events, the insights shared here will provide a real-world example of scaling a logging infrastructure for LLM applications. We'll cover our experience with serverless architecture using Cloudflare Workers and how we integrated it with Kafka for efficient log processing at scale.
The Initial Architecture and Its Limitations
Let's start by examining our initial serverless architecture and its limitations. It worked as follows:
- A client initiates an LLM request, which is proxied through Helicone’s Cloudflare workers to the desired LLM provider.
- After receiving the provider’s response and returning it to the client, we process the log with our business logic and insert it into databases.
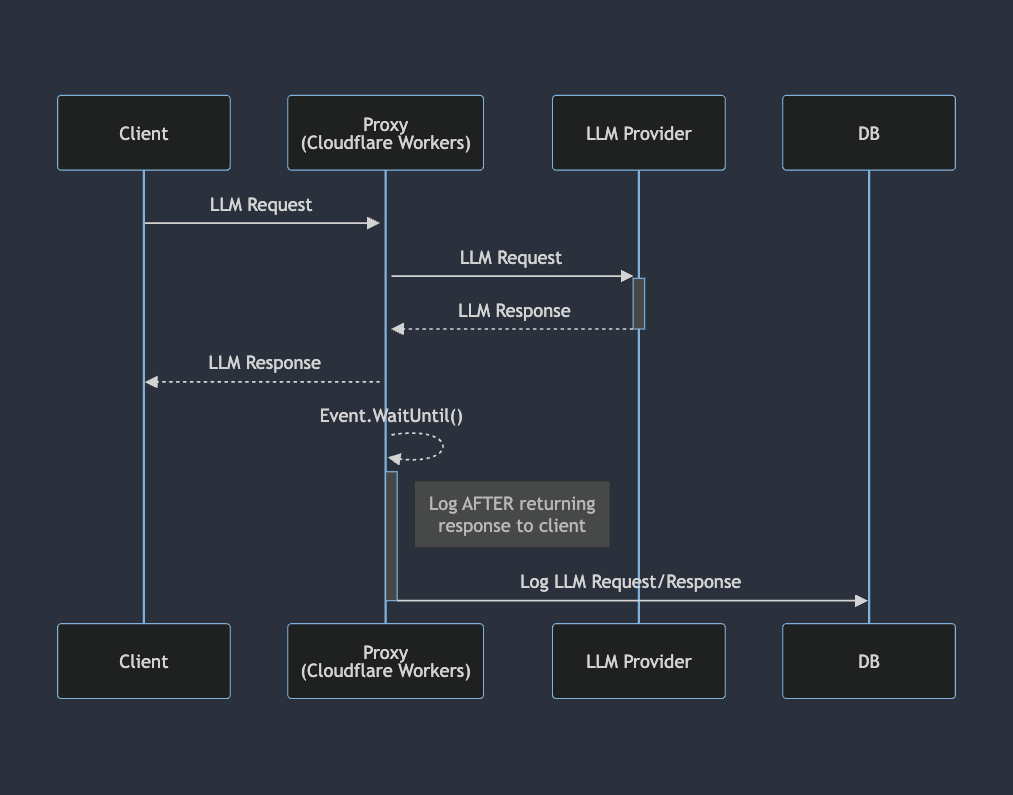
Why Didn't Our Initial Setup Scale?
Our initial architecture faced several significant challenges:
- Inefficient Event Processing: We were processing logs one at a time, a method that doesn't scale well with high-volume data.
- Data Loss During Downtime: Any service interruption meant lost logs and important data.
- Limited Reprocessing: When bugs caused incorrectly processed logs, we lacked robust means to reprocess them.
- Cloudflare Worker Limits: Cloudflare Workers have strict limits on memory, CPU, and execution time for
event.waitUntil, making it hard to handle growing log volumes.
All these issues resulted in frequent downtimes and lost logs, especially as our traffic surged. We needed a scalable and reliable solution urgently!
Introducing Upstash Kafka
Realizing the Need for a Persistent Queue
Increasing traffic and logging challenges highlighted the need for a persistent queue. Persistent queues decouple logging from our proxy, preventing data loss during downtimes, enabling batch log processing, and buffering traffic spikes to avoid database overload.
Why Kafka?
After evaluating several queue solutions, we chose Kafka for its unique advantages in high-volume data streaming:
- High Throughput: Kafka efficiently handles millions of messages per second, far surpassing traditional messaging queues.
- Persistence: Unlike many message queues, Kafka stores data on disk, allowing for replay and longer retention of messages.
- Distributed System: Kafka's architecture of topics and partitions allows for easy scaling and parallel processing.
Choosing Upstash Kafka
We compared Kafka with other solutions based on our core requirements:
| Criteria | AWS MSK | Redpanda Cloud | Upstash Kafka | | --------------------------- | -------------------------------------- | ----------------------------------------------------- | ------------------------------------------------------------------ | | Managed Service | ✓ | ✓ | ✓ | | HTTP Endpoint | ✗ | ✗ | ✓ | | Quick Setup and Integration | ✗ | ✓ | ✓ | | Reasonable Pricing | ✗ | ✓ | ✓ | | Excellent Support | ✓ | ✓ | ✓ |
Upstash Kafka offers a fully managed Kafka cluster with an HTTP endpoint, perfect for our Cloudflare Workers serverless architecture. Its quick setup, reasonable pricing, and excellent support made it the best choice.
Note: While we chose Upstash Kafka for our implementation, the principles and architecture discussed in this blog are applicable to other Kafka deployments and managed Kafka services.
Implementing Kafka
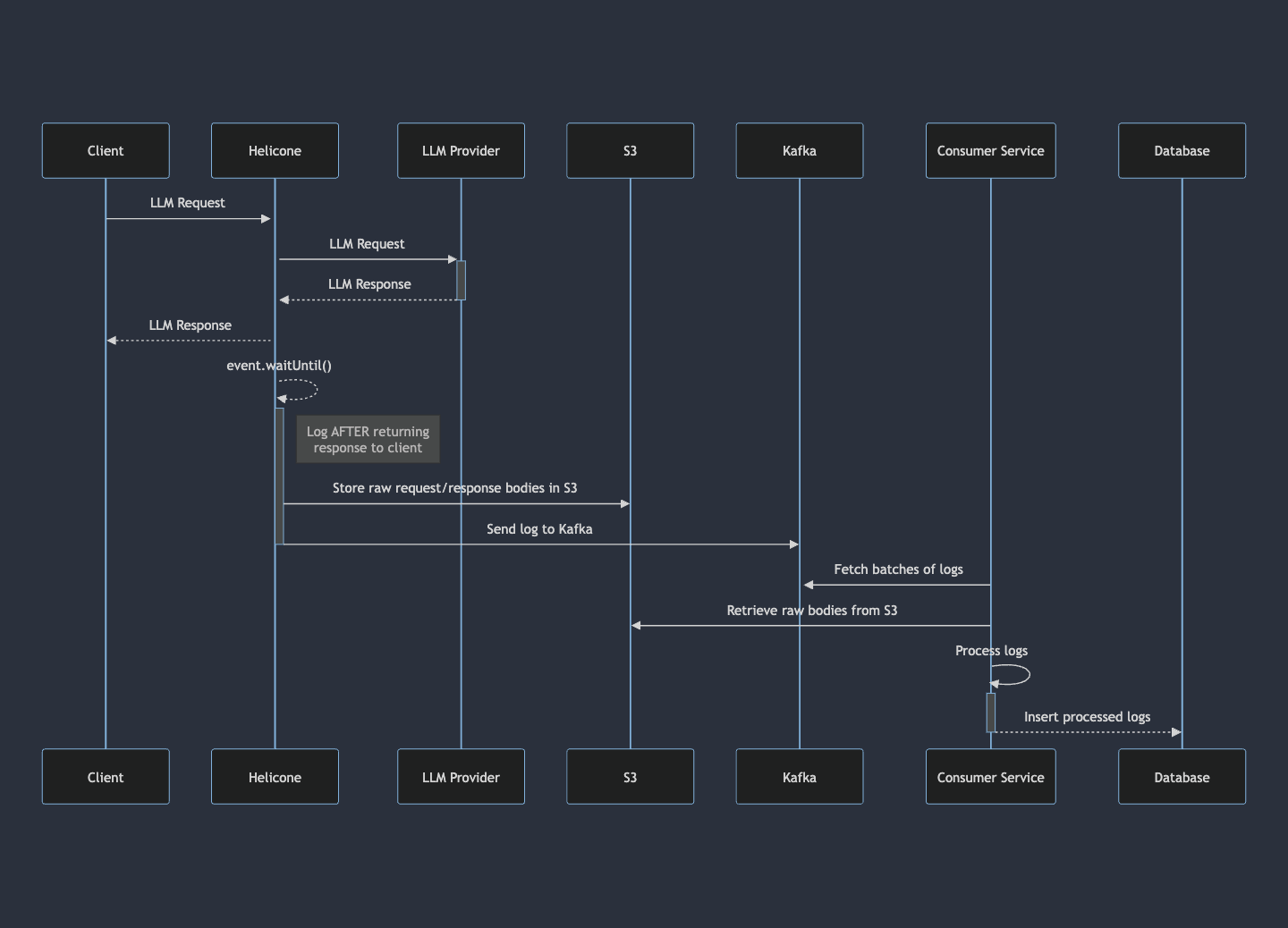
Here's a sequence diagram illustrating the new data flow:
- A client initiates an LLM request, which is proxied through Helicone’s proxy to the desired LLM provider.
- After receiving the provider's response and sending it to the client, we store the raw request/response bodies in S3. We then publish the rest directly to Kafka before any processing.
- Our ECS consumer service consumes batches of logs from Kafka, processes them asynchronously and inserts the entire batch in a single DB transaction.
Kafka Cluster Configuration
Upstash handles most of the configuration, like Kafka Brokers and Kafka Replication Factors. For what we do control, here's our setup:
Topics
Topics are used to organize and categorize messages in Kafka. Each topic corresponds to a specific type of data. For our use case involving LLM logs, we have two topics:
request-response-logs: This topic stores logs of all LLM requests and responses.- Configuration: 30 partitions, 7-day retention, 1TB storage capacity.
request-response-dlq: This topic serves as a dead-letter queue for logs that failed processing in the main logs topic.- Configuration: 15 partitions, 7-day retention, 1TB storage capacity.
These topics store messages with the following structure:
// Message topics contain
export type KafkaMessage = {
id: string;
heliconeMeta: HeliconeMeta;
log: Log;
};
// Actual log of LLM request/response
export type Log = {
request: {
id: string;
userId: string;
promptId?: string;
promptVersion?: string;
properties: Record<string, string>;
heliconeApiKeyId?: number;
heliconeProxyKeyId?: string;
targetUrl: string;
provider: Provider;
bodySize: number;
path: string;
threat?: boolean;
countryCode?: string;
requestCreatedAt: Date;
isStream: boolean;
heliconeTemplate?: TemplateWithInputs;
};
response: {
id: string;
status: number;
bodySize: number;
timeToFirstToken?: number;
responseCreatedAt: Date;
delayMs: number;
};
};
// Helicone metadata a user can optionally provide
export type HeliconeMeta = {
modelOverride?: string;
omitRequestLog: boolean;
omitResponseLog: boolean;
webhookEnabled: boolean;
posthogHost?: string;
};Note: We avoid sending bodies in Kafka messages because LLM bodies can be several megabytes, including images, videos, and audio. Large messages can impact Kafka's performance. Instead, we upload raw bodies to S3 and include references to the S3 locations in Kafka messages.
Partitions
Partitions in Kafka distribute data across brokers, enabling parallel processing and higher throughput. They're key to Kafka's scalability.
Our Setup:
- 30 partitions for
request-response-logstopic - 15 partitions for
request-response-logs-dlqtopic
We chose these numbers based on our expected throughput and Upstash's support for up to 100 partitions without extra cost. We increased partition count over time to handle growing data volumes and traffic spikes.
Note: Since we're not concerned about message order across the entire topic, using multiple partitions is fine. Kafka guarantees message order within each partition. If you need strict ordering of all messages in a topic, you would need to use a single partition or implement custom ordering logic in your consumer.
Consumers
Consumers are processes that read and process data from Kafka partitions.
Our Setup:
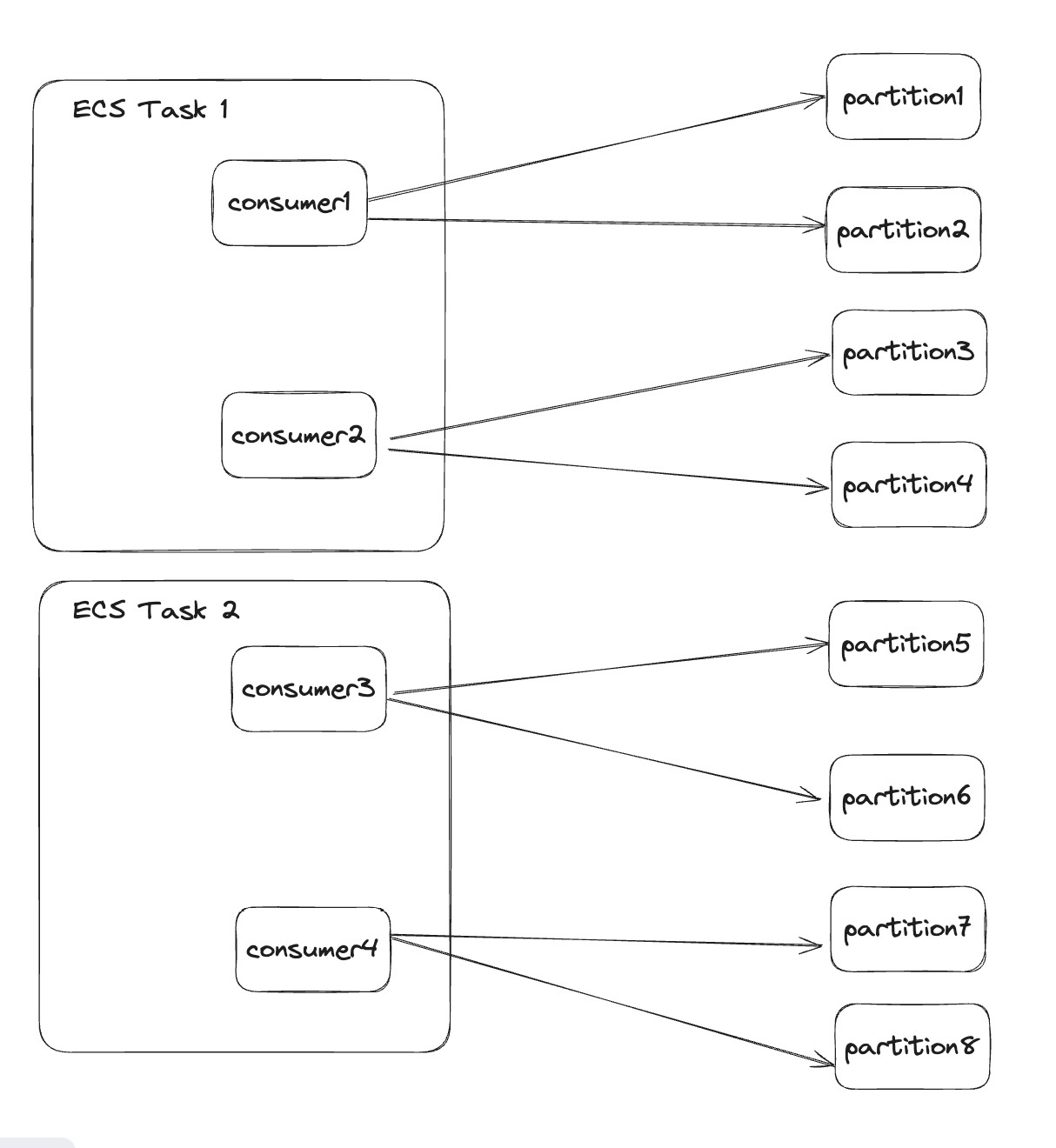
- Consumer Group: All consumers share the same consumer group to prevent duplicate data reads. Only one consumer per group reads from a given partition at a time as we only have 1 service consuming the logs.
- ECS Configuration: Our service runs in ECS with 4 vCPUs and 12GB of memory. We prioritize horizontal scaling of smaller ECS tasks for better fault tolerance, load distribution, and reduced resource contention.
- Task Allocation: Each ECS task runs 3 consumers for
request-response-logsand 1 consumer forrequest-response-dlq, determined by monitoring CPU and memory usage. - Partition Allocation: We run 5 ECS tasks, where consumers for
request-response-logsconnect to 2 partitions each, and consumers forrequest-response-dlqconnect to 3 partitions each.request-response-logs: 30 partitions / (5 tasks * 3 consumers) = 2 partitions per consumerrequest-response-dlq: 15 partitions / (5 tasks * 1 consumer) = 3 partitions per consumer
- Scaling Strategy: If we encounter a backlog on Kafka, we can double our consumption rate by scaling to 10 ECS tasks. This allows each consumer to read from a single partition, enabling more parallel processing. With 30 partitions and 10 tasks (3 consumers each), each consumer handles 1 partition.
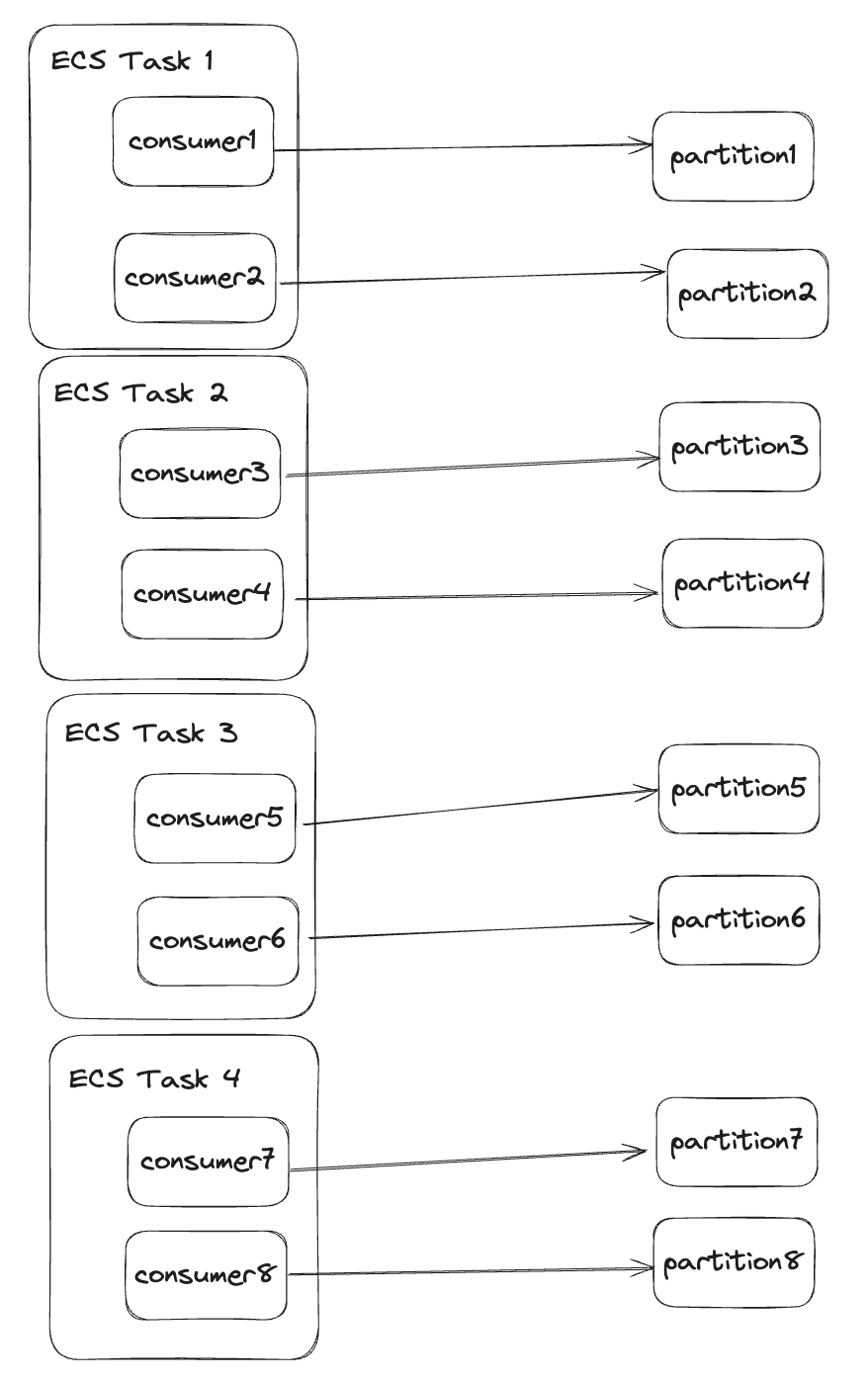
Example: 1 topic, 8 partitions, 2 consumers per ECS task with the same consumer group name. Kafka will load balance and distribute the partitions evenly among the consumers.
If there's a spike and 4 consumers aren't keeping up, we can add 2 more ECS tasks. Kafka will rebalance, and each consumer will handle a single partition.
Code Time
simplified for brevity. to view the full implementation, check out our open source repo
Implement the Kafka Producer
In our proxy running on Cloudflare Workers, we use the @upstash/kafka npm package. It simplifies sending messages via HTTP.
- Install the Upstash Kafka npm package
npm i @upstash/kafka- Initialize the Kafka client in a Kafka producer wrapper class
export class KafkaProducer {
private kafka: Kafka | null = null;
constructor(env: Env) {
this.kafka = new Kafka({
url: env.UPSTASH_KAFKA_URL,
username: env.UPSTASH_KAFKA_USERNAME,
password: env.UPSTASH_KAFKA_PASSWORD,
});
}
}- Implement the function within that class to produce the message. The KafkaMessage object being sent is shown above.
export class KafkaProducer {
// ...
async sendMessage(msg: KafkaMessage) {
if (!this.kafka) {
return;
}
// Get the producer
const p = this.kafka.producer();
// Prepare the message
const message = JSON.stringify({
value: JSON.stringify(msg),
});
// Produce the message
const res = await p.produce("request-response-logs", message, {
key: msg.log.request.id,
});
}
}Implement the Kafka Consumers
Since the consumers are running in ECS tasks, we can connect to the Kafka topics via TCP. To do this, I used the kafkajs package.
- Install the kafkajs npm package
npm i kafkajs- Implement a method to initialize the Kafka client
const KAFKA_CREDS = JSON.parse(process.env.KAFKA_CREDS ?? "{}");
const KAFKA_ENABLED = (KAFKA_CREDS?.KAFKA_ENABLED ?? "false") === "true";
const KAFKA_BROKER = KAFKA_CREDS?.UPSTASH_KAFKA_BROKER;
const KAFKA_USERNAME = KAFKA_CREDS?.UPSTASH_KAFKA_USERNAME;
const KAFKA_PASSWORD = KAFKA_CREDS?.UPSTASH_KAFKA_PASSWORD;
export function getKafka() {
if (KAFKA_ENABLED && KAFKA_BROKER && KAFKA_USERNAME && KAFKA_PASSWORD) {
return new Kafka({
brokers: [KAFKA_BROKER],
sasl: {
mechanism: "scram-sha-512",
username: KAFKA_USERNAME,
password: KAFKA_PASSWORD,
},
ssl: true,
logLevel: logLevel.ERROR,
});
} else {
console.error("Required Kafka environment variables are not set.");
}
}- Create the Kafka consumer worker threads
We create multiple consumers per task, each with its own dedicated worker thread.
import { Worker } from "worker_threads";
export function startConsumers({
normalCount, // 3
dlqCount, // 1
}: {
normalCount: number;
dlqCount: number;
}) {
for (let i = 0; i < normalCount; i++) {
const worker = new Worker(`${__dirname}/kafkaConsumer.js`);
worker.postMessage("start");
}
for (let i = 0; i < dlqCount; i++) {
const workerDlq = new Worker(`${__dirname}/kafkaConsumer.js`);
workerDlq.postMessage("start-dlq");
}
}- Create the Kafka consumer
Consumer configuration depends on specific goals. For us, high maxBytes allows large batches we split into mini-batches, logging offsets as we process. This provides fine-grained mini-batch size control without the need for consumer recreation.
export function generateKafkaConsumer(
groupId: "jawn-consumer",
): Consumer | undefined {
const kafka = getKafka();
if (!kafka) {
console.error("Failed to initialize Kafka client");
return undefined;
}
// Initialize consumer with configuration
const consumer = kafka.consumer({
groupId,
heartbeatInterval: 3000,
sessionTimeout: 3 * 60 * 1000, // 3 minutes
maxBytes: 50_000_000, // 50MB ~ 10,000 messages
});
// Set up error handling and graceful shutdown (IMPORTANT, implementation shown below)
setupErrorHandlers(consumer);
setupSignalTraps(consumer);
return consumer;
}- ❗
IMPORTANTSet up consumer graceful shutdowns
Ensure you disconnect the consumer as I do. Otherwise, ghost consumers might hog partitions. Handle all error types or signals gracefully to avoid this issue.
function setupErrorHandlers(consumer: Consumer) {
const errorTypes = ["unhandledRejection", "uncaughtException"];
errorTypes.forEach((type) => {
process.on(type, async (e) => {
try {
console.log(`Caught ${type}:`, e);
await gracefulShutdown(consumer);
} catch (_) {
process.exit(1);
}
});
});
}
function setupSignalTraps(consumer: Consumer) {
const signalTraps = ["SIGTERM", "SIGINT", "SIGUSR2"];
signalTraps.forEach((type) => {
process.once(type, async () => {
try {
await gracefulShutdown(consumer);
} finally {
process.kill(process.pid, type);
}
});
});
}
async function gracefulShutdown(consumer: Consumer) {
console.log("Disconnecting consumer...");
await consumer.disconnect();
console.log("Consumer disconnected. Exiting process.");
process.exit(0);
}- Configure the actual consumption logic
Note: The mini batch logic has been removed for simplicity sake. If you would like to view that, head over to our repo.
export const consume = async () => {
// Initialize Kafka consumer
const consumer = generateKafkaConsumer("jawn-consumer");
// Connect to Kafka (I recommend retries w/ exponential backoff)
await consumer?.connect();
// Subscribe to the topic
await consumer?.subscribe({
topic: "request-response-logs",
fromBeginning: true,
});
// Run the consumer. Use eachBatch instead of eachMessage if you want to consume in batches.
// eachBatchAutoResolve: false because we resolve the offsets manually
await consumer?.run({
eachBatchAutoResolve: false,
eachBatch: async ({
batch,
resolveOffset,
heartbeat,
commitOffsetsIfNecessary,
}) => {
try {
// Map Kafka messages to our internal message format
const mappedMessages = mapKafkaMessageToMessage(batch.messages);
// Process the entire batch
const consumeResult = await consumeBatch(
mappedMessages.data,
batch.partition,
"request-response-logs",
);
} catch (error) {
console.error("Failed to process batch", error);
} finally {
// Update Kafka offsets and perform heartbeat
const lastOffset = batch.messages[batch.messages.length - 1]?.offset;
if (lastOffset) {
resolveOffset(lastOffset);
}
await heartbeat();
await commitOffsetsIfNecessary();
}
},
});
};Kafka Batch Processing: Challenges and Solutions
Challenges
- Batch Handling Complexity: Processing Kafka messages in batches requires significant backend changes, especially for database operations.
- HTTP Connection Limits: Processing multiple logs asynchronously can overwhelm HTTP connections.
- Session Timeout: Long-running batch processes may cause Kafka consumer disconnections.
- Data Duplication: Kafka's at-least-once delivery guarantee means you may process the same data multiple times.
- Partial Data Processing: Batch failures midway can leave data in an inconsistent state and will need to be rolled back or reprocessed.
Solution: Our Backend Rewrite
From handling single events in Cloudflare Workers to processing batches in our Express service running in ECS, here's how we implemented it:
We use a chain of responsibility pattern that lets us add new handlers to process each log individually. This approach makes it easy to insert new handlers wherever needed within the chain.
const authHandler = new AuthenticationHandler();
const rateLimitHandler = new RateLimitHandler(new RateLimitStore());
const s3Reader = new S3ReaderHandler(s3Client);
const requestHandler = new RequestBodyHandler();
const responseBodyHandler = new ResponseBodyHandler();
const promptHandler = new PromptHandler();
const loggingHandler = new LoggingHandler(
new LogStore(),
new VersionedRequestStore(""),
s3Client,
);
const posthogHandler = new PostHogHandler();
const lytixHandler = new LytixHandler();
const webhookHandler = new WebhookHandler(
new WebhookStore(supabaseServer.client),
new FeatureFlagStore(supabaseServer.client),
);
authHandler
.setNext(rateLimitHandler)
.setNext(s3Reader)
.setNext(requestHandler)
.setNext(responseBodyHandler)
.setNext(promptHandler)
.setNext(loggingHandler)
.setNext(posthogHandler)
.setNext(lytixHandler)
.setNext(webhookHandler);
await Promise.all(
logMessages.map(async (logMessage) => {
const handlerContext = new HandlerContext(logMessage);
const result = await authHandler.handle(handlerContext);
}),
);Once all the processed log data is stored in memory, we then handle the batch processes:
await this.logRateLimits(rateLimitHandler, batchContext);
await this.logHandlerResults(loggingHandler, batchContext, logMessages);
await this.logPosthogEvents(posthogHandler, batchContext);
await this.logLytixEvents(lytixHandler, batchContext);
await this.logWebhooks(webhookHandler, batchContext);The most critical part of the batch process is logging to our Postgres and ClickHouse databases using logHandlerResults().
public async handleResults() {
// Insert into Postgres
await this.logStore.insertLogBatch(this.batchPayload);
// Upload to S3
await this.uploadToS3();
// Insert into ClickHouse
await this.logToClickhouse();
}To handle inserting into Postgres, we use pg-promise for client-side database transactions. We chose client-side transactions for easier debugging compared to stored procedures. Here's the code:
Note: Our implementation uses transactions for automatic rollback on failure and ON CONFLICT clauses for upserts. This approach accommodates Kafka's at-least-once delivery guarantee and allows for safe log replays if needed.
import pgPromise from "pg-promise";
const pgp = pgPromise();
const db = pgp(/* connection details */);
// Define column sets for tables
const requestColumns = new pgp.helpers.ColumnSet(
["id", "properties", "model" /* other columns */],
{ table: "request" },
);
const responseColumns = new pgp.helpers.ColumnSet(
["id", "completion_tokens", "delay_ms" /* other columns */],
{ table: "response" },
);
// On conflict clauses
const onConflictRequest =
" ON CONFLICT (id) DO UPDATE SET " +
requestColumns.assignColumns({ from: "EXCLUDED", skip: "id" });
const onConflictResponse =
" ON CONFLICT (request) DO UPDATE SET " +
responseColumns.assignColumns({ from: "EXCLUDED", skip: "id" });
export class LogStore {
async insertLogBatch(payload) {
try {
// Client-side transaction
await db.tx(async (t) => {
// Insert requests
if (payload.requests.length > 0) {
const insertRequest =
pgp.helpers.insert(payload.requests, requestColumns) +
onConflictRequest;
await t.none(insertRequest);
}
// Insert responses
if (payload.responses.length > 0) {
const insertResponse =
pgp.helpers.insert(payload.responses, responseColumns) +
onConflictResponse;
await t.none(insertResponse);
}
// Other operations...
});
return "Successfully inserted log batch";
} catch (error) {
return "Failed to insert log batch: " + error;
}
}
}Now, we only log in ClickHouse if the Postgres transaction was successful. To handle duplicates and repair bad data in ClickHouse, we use a VersionedCollapsingMergeTree. The details which I will not go into in this blog.
Conclusion
That's a wrap on our Kafka journey! By implementing Kafka with Cloudflare Workers, we've successfully scaled our logging infrastructure to handle billions of LLM logs. This solution decoupled log ingestion from processing, enabled efficient batch processing, and provided flexibility for both real-time and historical data analysis. While complex, this architecture has proven robust for high-volume, variable-load scenarios common in AI applications.
Helicone
We're an open-source LLM observability platform that provides deep visibility into AI operations at scale. Our infrastructure, as described in this blog, allows us to handle billions of logs, offering real-time insights and analytics for your LLM applications. Whether you're a startup or an enterprise, Helicone helps you optimize performance, control costs, and ensure reliability. Ready to supercharge your AI observability? Visit Helicone.ai to get started.